I am starting a new series of posts called “Mathursday” (portmanteau: Maths+Thursday) containing short articles on important mathematical results. Today’s article is about Dynkin’s π-λ Theorem and using it to prove that a Cummulative Distribution Function (CDF) uniquely determines the probability distribution. This is one of the result that is quite intuitive and well known but requires a bit of analysis to formally prove or even to state. There are several such results in statistics that use similar techniques for proving. Generally, the treatment of these proofs is completely omitted in statistics book (like Wasserman). The alternative is to meander your way through mathematical course on probability theory to extract the result. In this series of posts, I hope to give a direct self-contained mathematical treatment.
The proof uses basic results and definition from two important areas of mathematics: topology and measure theory. This series is divided into two posts. The first post (this one) covers basic of the above fields. The aim here is not to reproduce a complete treatment as found in mathematical books but give a concise concentrated basic treatment of different topics. You can skip to the next post if you already know these basics.
Set Theory
A set  is a collection of some members. Each member in the set appears one time. It can be finite (e.g., natural numbers less than 20), countable (meaning it can be enumerated e.g., set of odd natural numbers) or uncountable (e.g., real numbers). A subset
is a collection of some members. Each member in the set appears one time. It can be finite (e.g., natural numbers less than 20), countable (meaning it can be enumerated e.g., set of odd natural numbers) or uncountable (e.g., real numbers). A subset 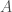 of (denoted as
of (denoted as 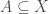 ) is a set containing only members of . Power set of a set (denoted as
) is a set containing only members of . Power set of a set (denoted as 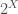 ) is the set of all subsets of . A set containing no members is called an empty set (denoted by
) is the set of all subsets of . A set containing no members is called an empty set (denoted by  ). The cardinality of a set
). The cardinality of a set 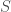 (denoted by
(denoted by 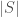 ) is the number of members in the set.
) is the number of members in the set.
For two sets and 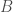 : their union (denoted
: their union (denoted  ) is a set containing all members of and ; their intersection (denoted
) is a set containing all members of and ; their intersection (denoted  ) is a set containing members common to and ; the set subtraction
) is a set containing members common to and ; the set subtraction 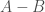 is a set obtained by removing all members of present in while retaining other members. If is a subset of then the complement set of is defined as
is a set obtained by removing all members of present in while retaining other members. If is a subset of then the complement set of is defined as  . Observe that for any two sets
. Observe that for any two sets  we have
we have 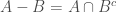 . There is a useful identity called De Morgan’s law which states, for any two sets :
. There is a useful identity called De Morgan’s law which states, for any two sets : 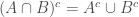 and
and  .
.
While the above may look all easy and simple, developing an axiom based version of set theory has been quite challenging. Naive set theory suffered from Russell’s paradox while modern attempts like ZFC had their own controversy. For our current purpose, we won’t go into these details.
General Topology
Definition (Topology): 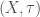 is called a topological space if is a set and
is called a topological space if is a set and  is a collection of subsets of called open sets that satisfy the following properties:
is a collection of subsets of called open sets that satisfy the following properties:
1) 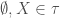
2)  is closed under countable union i.e, if
is closed under countable union i.e, if  then
then  .
.
3) is closed under finite intersection i.e., if  for
for  then
then 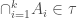 .
.
If satisfy these properties then it is called a topology on .
There is a reason why we call members of the topology as open set and this will become clear when we consider topology induced by metric spaces.
Example 1: For any set , the power set and 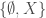 are topologies on . Let
are topologies on . Let  then
then 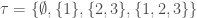 is a topology on .
is a topology on .
Definition (Metric Spaces): 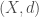 is a metric space if is a vector space and
is a metric space if is a vector space and 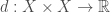 is a function satisfying the following properties for all
is a function satisfying the following properties for all 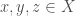 :
:
1)  (identity of indiscernibles)
(identity of indiscernibles)
2)  (symmetry)
(symmetry)
3)  (triangle inequality)
(triangle inequality)
If  satisfies the above properties then it is called a metric on .
satisfies the above properties then it is called a metric on .
Observe that setting  in the triangle inequality gives us
in the triangle inequality gives us  . Using symmetry we get
. Using symmetry we get 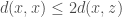 . As
. As 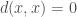 we get
we get 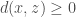 . Hence, is a non-negative valued function.
. Hence, is a non-negative valued function.
Example 2: Metric is supposed to abstract commonly used distance functions. For example, Minkowski distance 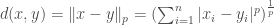 for
for ![p \in (0, \infty]](https://s0.wp.com/latex.php?latex=p+%5Cin+%280%2C+%5Cinfty%5D&bg=ffffff&fg=404040&s=0&c=20201002) is a metric function. It is straightforward to verify that
is a metric function. It is straightforward to verify that 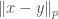 the first two property. Proving triangle inequality is more challenging and uses Minkowski’s inequality.
the first two property. Proving triangle inequality is more challenging and uses Minkowski’s inequality.
One can define various sort of interesting geometric subsets using the metric. For example, we can define a ball of radius  as
as  .
.
Metric spaces provide a way to induce a useful topology on . We define the topology induced by metric space as follows:

It is straightforward to verify that is a topology. It is interesting to note that if  and
and  , then open intervals
, then open intervals  (open in the geometric sense) are members of . This means our standard geometric notion of open set coincides with open set in topology. Unless mentioned otherwise, we will assume the topology defined on real number space
(open in the geometric sense) are members of . This means our standard geometric notion of open set coincides with open set in topology. Unless mentioned otherwise, we will assume the topology defined on real number space  to be the topology defined above using Euclidean distance as our choice of metric.
to be the topology defined above using Euclidean distance as our choice of metric.
Lemma 1: Every open set on 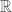 is a countable union of disjoint open intervals.
is a countable union of disjoint open intervals.
Proof: Let be an open set on . We define an equivalence relation  if
if ![[\min(x, y), \max(x, y)] \subseteq S](https://s0.wp.com/latex.php?latex=%5B%5Cmin%28x%2C+y%29%2C+%5Cmax%28x%2C+y%29%5D+%5Csubseteq+S&bg=ffffff&fg=404040&s=0&c=20201002) . It is easy to see that each equivalance class is an open interval for some
. It is easy to see that each equivalance class is an open interval for some 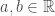 with
with 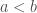 . Further, these open classes are disjoint else they can be merged together. Finally, for each equivalence class we can associate a rational number in the interval. The proof is completed by observing that the set of rational numbers is countable.
. Further, these open classes are disjoint else they can be merged together. Finally, for each equivalence class we can associate a rational number in the interval. The proof is completed by observing that the set of rational numbers is countable.
Measure Theory
Measure theory is a field of mathematics concerned with assigning value to subsets that provides a useful theoretical basis for probability theory, for defining Lebesgue integration and studying dynamical systems. Below we consider main concepts in measure theory that will be useful in our proof.
Definition (Algebra on Subsets): For a set , a nonempty collection of subsets  is an algebra of subsets if:
is an algebra of subsets if:
1. 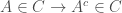 (closed under complement).
(closed under complement).
2. 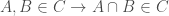 (closed under finite intersection).
(closed under finite intersection).
Lemma 2: If 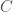 is an algebra on then
is an algebra on then  and for all
and for all 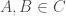 we have
we have 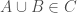 .
.
Proof: As is nonempty let 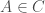 . Then
. Then  and
and  . From DeMorgan’s law:
. From DeMorgan’s law:  which belongs to as the algebra is closed under complement and finite intersections. Lastly,
which belongs to as the algebra is closed under complement and finite intersections. Lastly, 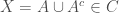 .
.
Definition (σ-algebra): For a set , a σ-algebra is an algebra on that is closed under countable union i.e., if 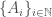 is a countable collection of sets in the σ–algebra then
is a countable collection of sets in the σ–algebra then 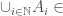 σ-algebra.
σ-algebra.
Observe that the second condition of algebra of subsets only implies it is closed under finite union and not closed under countable unions. For example, let consider a collection of subsets of which are finite or have finite complement. Then is an algebra and closed under finite union: union of any two members still yields a finite set (or a finite complement). But if we take countable unions of members of then we can get the set of natural numbers which are neither finite nor have a finite complement. Therefore, the countable union condition in σ-algebra makes it a strict generalization of algebra on subsets.
Using De Morgan’s law we can show that any σ-algebra is also closed under countable intersection: let 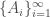 be a countable collection of sets in the σ-algebra. Then
be a countable collection of sets in the σ-algebra. Then 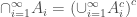 . As σ-algebra is closed under intersections and countable union therefore,
. As σ-algebra is closed under intersections and countable union therefore, 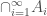 belongs to the σ-algebra. Another nice property of algebra of subsets and σ-algebra is that they are closed under countable intersection. We leave the proof as it is quite straightforward.
belongs to the σ-algebra. Another nice property of algebra of subsets and σ-algebra is that they are closed under countable intersection. We leave the proof as it is quite straightforward.
Lemma 2: A countable intersection of σ-algebras is also a σ-algebra.
The intersection property of σ-algebra allows us to define a useful notion: Given a subset 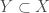 , we define
, we define  as the smallest σ-algebra that contains
as the smallest σ-algebra that contains 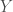 . This can be formally defined as:
. This can be formally defined as: 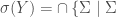 is a σ-algebra and
is a σ-algebra and  . This definition is well formed as the power set is always a σ-algebra containing any subset.
. This definition is well formed as the power set is always a σ-algebra containing any subset.
σ-algebra and Topology: One cannot fail to observe a remarkable similarity between the definition of σ-algebra and topology. Given a topology and σ-algebra on a set . Both contain the empty set and , and are closed under countable union. However, a topology is not closed under complement and is only closed under finite intersection. This difference stems from their different purpose. For example, assigning measure to a set intuitively suggests being able to assign measure to its complement.
In general, measure theory and topology do not always sync. One has to only look at the different topics in the two fields. However, there is an important interplay between topology and measure theory that allows us to talk about measure on top of open sets. Borel set captures this idea:
Definition (Borel Set): Given a topological space 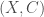 , the Borel σ-algebra
, the Borel σ-algebra 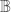 is the smallest σ-algebra generated by topology:
is the smallest σ-algebra generated by topology: 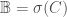 . A member of is called a Borel set.
. A member of is called a Borel set.
Lemma 3: For standard topology on , the Borel σ-algebra  on is given by:
on is given by:
1) 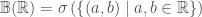
2) ![\mathbb{B}(\mathbb{R}) = \sigma\left(\left\{ (-\infty, a] \mid a \in \mathbb{R} \right\}\right)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BB%7D%28%5Cmathbb%7BR%7D%29+%3D+%5Csigma%5Cleft%28%5Cleft%5C%7B+%28-%5Cinfty%2C+a%5D+%5Cmid+a+%5Cin+%5Cmathbb%7BR%7D+%5Cright%5C%7D%5Cright%29&bg=ffffff&fg=404040&s=0&c=20201002)
3) 
4) 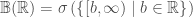
5) 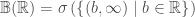
Proof: We prove the first two case. The proof for remaining case is similar.
1. From Lemma 1, any open set in is generated by a countable union of disjoint open intervals. As σ-algebra is closed under countable union so 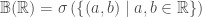 .
.
2. Let ![A = \sigma\left(\left\{ (-\infty, a] \mid a \in \mathbb{R} \right\}\right)](https://s0.wp.com/latex.php?latex=A+%3D+%5Csigma%5Cleft%28%5Cleft%5C%7B+%28-%5Cinfty%2C+a%5D+%5Cmid+a+%5Cin+%5Cmathbb%7BR%7D+%5Cright%5C%7D%5Cright%29&bg=ffffff&fg=404040&s=0&c=20201002) . As is closed under complement therefore, we can also express:
. As is closed under complement therefore, we can also express:  . However,
. However, 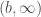 is an open set and is a σ-algebra generated by a collection of open sets. Therefore,
is an open set and is a σ-algebra generated by a collection of open sets. Therefore,  .
.
Let then ![(-\infty, b], (a, \infty) \in A](https://s0.wp.com/latex.php?latex=%28-%5Cinfty%2C+b%5D%2C+%28a%2C+%5Cinfty%29+%5Cin+A&bg=ffffff&fg=404040&s=0&c=20201002) . As a σ-algebra is closed under intersection, therefore,
. As a σ-algebra is closed under intersection, therefore, ![(a, b] = (-\infty, b] \cap (a, \infty) \in A](https://s0.wp.com/latex.php?latex=%28a%2C+b%5D+%3D+%28-%5Cinfty%2C+b%5D+%5Ccap+%28a%2C+%5Cinfty%29+%5Cin+A&bg=ffffff&fg=404040&s=0&c=20201002) . It can now be shown that any open interval can be generated from countable union:
. It can now be shown that any open interval can be generated from countable union: ![(a, b) = \cup_{n=1}^\infty \left(a, b - \frac{1}{n}\right] \in A](https://s0.wp.com/latex.php?latex=%28a%2C+b%29+%3D+%5Ccup_%7Bn%3D1%7D%5E%5Cinfty+%5Cleft%28a%2C+b+-+%5Cfrac%7B1%7D%7Bn%7D%5Cright%5D+%5Cin+A&bg=ffffff&fg=404040&s=0&c=20201002) . As contains open interval therefore, it contains all member of (using our proof of case 1). This implies
. As contains open interval therefore, it contains all member of (using our proof of case 1). This implies 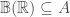 . Hence,
. Hence,  .
.
Definition (Measurable Space): A measurable space is a tuple 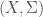 where is a set and
where is a set and  is a σ-algebra on .
is a σ-algebra on .
Example 3:  is a measurable space where the real number line is the set and set of all Borel sets is our σ-algebra.
is a measurable space where the real number line is the set and set of all Borel sets is our σ-algebra.
The next notion is useful in defining the notion of random variables in probability theory.
Definition (Measurable Function): A function 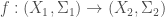 is called measurable if
is called measurable if  are measurable spaces, and
are measurable spaces, and 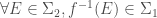 .
.
In the above definition:  . The job of measurable functions is to ensure that we stick to members in σ-algebras when doing calculations.
. The job of measurable functions is to ensure that we stick to members in σ-algebras when doing calculations.
Definition (Measure): Let be a set and be a σ-algebra on . A measure ![\mu: \Sigma \rightarrow [0, \infty]](https://s0.wp.com/latex.php?latex=%5Cmu%3A+%5CSigma+%5Crightarrow+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=404040&s=0&c=20201002) is a function satisfying the following property:
is a function satisfying the following property:
1. 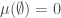 (null empty set)
(null empty set)
2. If  be a countable collection of pairwise disjoint members of then
be a countable collection of pairwise disjoint members of then 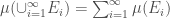 (σ-additivity).
(σ-additivity).
The σ-additivity condition also holds for a finite set: let 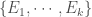 be a set of pairwise disjoint members of . Then define
be a set of pairwise disjoint members of . Then define 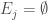 for all values of
for all values of 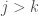 . Then is an infinite countable set of pairwise disjoint members (Yes,
. Then is an infinite countable set of pairwise disjoint members (Yes,  are disjoint). Therefore,
are disjoint). Therefore,  . The last equality used .
. The last equality used .
A measure is called finite if 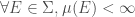 . If for any member
. If for any member 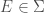 we have
we have 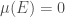 then we call
then we call  a null set. Intuitively, null set denotes the smallest subsets in the σ-algebra.
a null set. Intuitively, null set denotes the smallest subsets in the σ-algebra.
Example 4: If is finite and the σ-algebra is the power set then 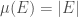 is a measure. This measure is called the counting measure.
is a measure. This measure is called the counting measure.
Measures are intuitively supposed to generalize the common notion of length, area, and volume. In general however, constructing a useful measure such as Lebesgue measure is quite challenging. See Hunter’s lecture note on measure theory for full treatment.
Definition (Probability Measure):Let be a set and be a σ-algebra on . A probability measure 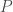 is a measure with the unitarity property that states:
is a measure with the unitarity property that states: 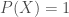 .
.
When talking about probability measures, we understand as the set of elementary outcomes and as a collection of events. For example, say we flip a coin two times then an elementary outcome is ![[H, H]](https://s0.wp.com/latex.php?latex=%5BH%2C+H%5D&bg=ffffff&fg=404040&s=0&c=20201002) indicating two heads, and an event would be outcomes with at least one heads.
indicating two heads, and an event would be outcomes with at least one heads.
The need for σ-algebra: The definition of σ-algebra looks opaque. Why cannot we simply use the power set to define the domain of our measure? The answer to this question has an interesting history which arises from the discovery of non-measurable sets at the beginning of 20th century. Mathematicians found that if we consider all possible subsets of for defining a measure, then no function exists that satisfies the above properties and generalizes the notion of length of an interval i.e., ![\mu([a, b]) = b-a](https://s0.wp.com/latex.php?latex=%5Cmu%28%5Ba%2C+b%5D%29+%3D+b-a&bg=ffffff&fg=404040&s=0&c=20201002) ! Interesting non-measurable sets like the Vitali set were discovered. The concept of σ-algebra was, therefore, used to narrow down the choice of subsets while maintaining useful properties. For example, if we talk about the probability of an event then we may also want to consider the probability of it not taking place i.e.,
! Interesting non-measurable sets like the Vitali set were discovered. The concept of σ-algebra was, therefore, used to narrow down the choice of subsets while maintaining useful properties. For example, if we talk about the probability of an event then we may also want to consider the probability of it not taking place i.e., 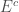 hence our σ-algebra must contain .
hence our σ-algebra must contain .
Definition (Measure Space and Probability Space): A measure space is a tuple  where is a measurable space and
where is a measurable space and  is a measure on . A measure space is called a probability space if is a probability measure i.e.,
is a measure on . A measure space is called a probability space if is a probability measure i.e.,  .
.
Definition (Random Variables): A real-valued random variable 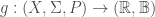 is a measurable function from a probability space
is a measurable function from a probability space  to the measurable space .
to the measurable space .
When considering the measurability of the random variable we ignore the probability measure and consider as our input measurable space. Further, even though we consider Borel σ-algebra as our choice of σ-algebra on we can use any other σ-algebra.
Cummulative Distribution Function: Given a random variable , the cummulative distribution function (CDF) is a function ![G: \mathbb{R} \rightarrow [0, 1]](https://s0.wp.com/latex.php?latex=G%3A+%5Cmathbb%7BR%7D+%5Crightarrow+%5B0%2C+1%5D&bg=ffffff&fg=404040&s=0&c=20201002) defined as
defined as ![G(z) = P(g^{-1}((-\infty, z]))](https://s0.wp.com/latex.php?latex=G%28z%29+%3D+P%28g%5E%7B-1%7D%28%28-%5Cinfty%2C+z%5D%29%29&bg=ffffff&fg=404040&s=0&c=20201002) .
.
This definition is a bit involved. Firstly, observe that the closed ray ![(-\infty, z] \in \mathbb{B}](https://s0.wp.com/latex.php?latex=%28-%5Cinfty%2C+z%5D+%5Cin+%5Cmathbb%7BB%7D&bg=ffffff&fg=404040&s=0&c=20201002) for any value of
for any value of 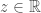 . Therefore, as random variable is a measurable function we have
. Therefore, as random variable is a measurable function we have ![g^{-1}((-\infty, z]) \in \Sigma](https://s0.wp.com/latex.php?latex=g%5E%7B-1%7D%28%28-%5Cinfty%2C+z%5D%29+%5Cin+%5CSigma&bg=ffffff&fg=404040&s=0&c=20201002) . As is a probability measure on therefore
. As is a probability measure on therefore ![P(g^{-1}((-\infty, z]))) \in [0, 1]](https://s0.wp.com/latex.php?latex=P%28g%5E%7B-1%7D%28%28-%5Cinfty%2C+z%5D%29%29%29+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=404040&s=0&c=20201002) .
.
The reason it is called CDF is since we can think of it as the total accumulated probability measure assigned to the outcomes that give a value of less than equal to  , as we vary from
, as we vary from  to
to  . It is straightforward to verify that CDF is a non-decreasing function. Further, it can be easily shown that
. It is straightforward to verify that CDF is a non-decreasing function. Further, it can be easily shown that 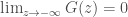 and
and  .
.
We are now ready to state the main theorem that we prove in the next post.
Theorem: Let 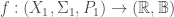 and
and  be two random variables with CDF
be two random variables with CDF 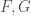 respectively. If
respectively. If 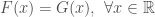 then
then 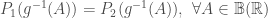 .
.
We do not require the two random variables to even have the same input space or σ-algebra. The theorem states that if two real-valued random variables have the same CDF then they have the same induced distribution over the real number line.
